
A inteligência artificial na apreciação de reclamações pela ERS
Introdução
A ERS é uma entidade administrativa independente, que tem por missão a regulação e supervisão da atividade de todos os estabelecimentos prestadores de cuidados de saúde.
Considerando as atribuições e competências da ERS relativamente à defesa dos direitos e interesses legítimos dos utentes dos serviços de saúde, de entre as demais áreas de intervenção regulatória, a Reguladora tem como incumbência apreciar as reclamações sobre estabelecimentos prestadores de cuidados de saúde e monitorizar o seguimento que lhes é por estes dispensado.
No cumprimento da sua missão e em conformidade com seus estatutos, a ERS recolhe diariamente dados relativos à atividade dos prestadores de cuidados de saúde e à perceção dos utentes sobre os mesmos.
É no âmbito da recolha de grandes volumes de dados nesta área de apreciação de reclamações, que a Inteligência Artificial surge como um importante instrumento de apoio à análise e tomada de decisão.
Foi neste contexto que surgiu o presente projeto[1], que visa a apreciação de reclamações privilegiando técnicas de análise associadas a modelos de Inteligência Artificial, e denominado Comportamento Preditivo na Saúde.
![]()
[1] Projeto cofinanciado com referência POCI-05-5762-FSE-000205 ![]()
Caraterização do processo atual
As atividades da ERS na apreciação das reclamações implicam uma análise qualitativa sobre a informação recebida, tanto ao nível processual de tramitação da reclamação, como do seu conteúdo material.
Atualmente, a ERS tem implementado um processo diário de seleção, leitura e apreciação de reclamações, que tem como requisito a ordenação e priorização das reclamações para apreciação, de acordo com a gravidade dos temas/ assuntos[2] dos factos reclamados.
Os técnicos da ERS tramitam individualmente cada reclamação, elogio e sugestão (doravante designado por processo REC[3]), já classificados previamente por temas/ assuntos pelos prestadores de cuidados de saúde, e ordenados consoante a sua relevância, reclassificando-os sempre que necessário.
Adicionalmente, a ERS já promove a análise transversal de tendências no comportamento do setor regulado, através da identificação de múltiplas reclamações associadas entre s.
Nesse sentido, e sem prejuízo do automatismo já associado ao processo de leitura e tramitação de processos REC, considerou-se fundamental evoluir e munir a ERS de novos mecanismos que permitissem obter uma triagem assertiva das reclamações recebidas e garantir a qualidade na sua priorização para análise.
Objetivos
A execução do projeto tem os seguintes objetivos:
⦁ Criação de um processo automático para extração de informação de reclamações através de métodos de Inteligência Artificial, nomeadamente a análise de linguagem natural, para automatizar a criação de informação estruturada;
⦁ Aplicação de métodos de Inteligência Artificial para a criação de modelos de aprendizagem automática para classificação automática de reclamações e comunicações relacionadas;
⦁ Criação de modelos de identificação e análise automática de padrões e tendências na atuação dos prestadores de cuidados de saúde dada a perceção dos utentes, com recurso à inteligência artificial;
⦁ Disponibilização de ferramentas de exploração dos modelos de Inteligência Artificial para análise de correlações entre dados decorrentes de diversas fontes internas de informação da ERS (nomeadamente, reclamações, ações de fiscalização, processos de licenciamento e procedimentos administrativos) e/ou organizados por tipologia de cuidados, natureza dos prestadores, região, entre outras relações que possam emergir em fase de análise;
⦁ Disponibilização de ferramentas de exploração dos modelos de Inteligência Artificial para análise, incluindo a possibilidade de utilização de dados externos à ERS (p.e, dados de caraterização da população);
⦁ Criação de sistema de alarmística inteligente que disponibilize alarmes automáticos de acordo com os modelos (p.e., proposta de realização de determinadas ações de fiscalização com base em padrões de reclamações).
⦁ Otimização de processos internos e metodologias de trabalho da ERS, melhorando a eficácia e a eficiência no tratamento das reclamações.
Plano de trabalhos
Para o cumprimento dos objetivos do projeto foram definidas duas fases:
FASE A - diz respeito ao conjunto de atividades de análise do problema, seleção de modelos de Inteligência Artificial, teste e validação dos modelos, desenvolvimento e testes do protótipo;
FASE B - corresponde à implementação do sistema em ambiente real, divulgação e apresentação de resultados.
A solução
Foi desenhada uma solução para melhorar e apoiar o tratamento das reclamações inseridas no sistema de gestão de reclamações da ERS (SGREC).
A solução prevê a interação entre o SGREC e o módulo de Inteligência Artificial durante todo o processo de tramitação de uma reclamação, desde a sua submissão à decisão final da ERS.
Esta solução permite (1) a (re)classificação das reclamações por temas/ assuntos, (2) a atribuição de um nível de gravidade à reclamação de acordo com a aplicação de uma matriz de risco, (3) a emissão de eventuais alertas à ERS (4) a identificação de reclamações duplicadas e relacionadas e (5) dar sugestões à ERS de apoio à decisão dos processos, com base no histórico de intervenção regulatória.
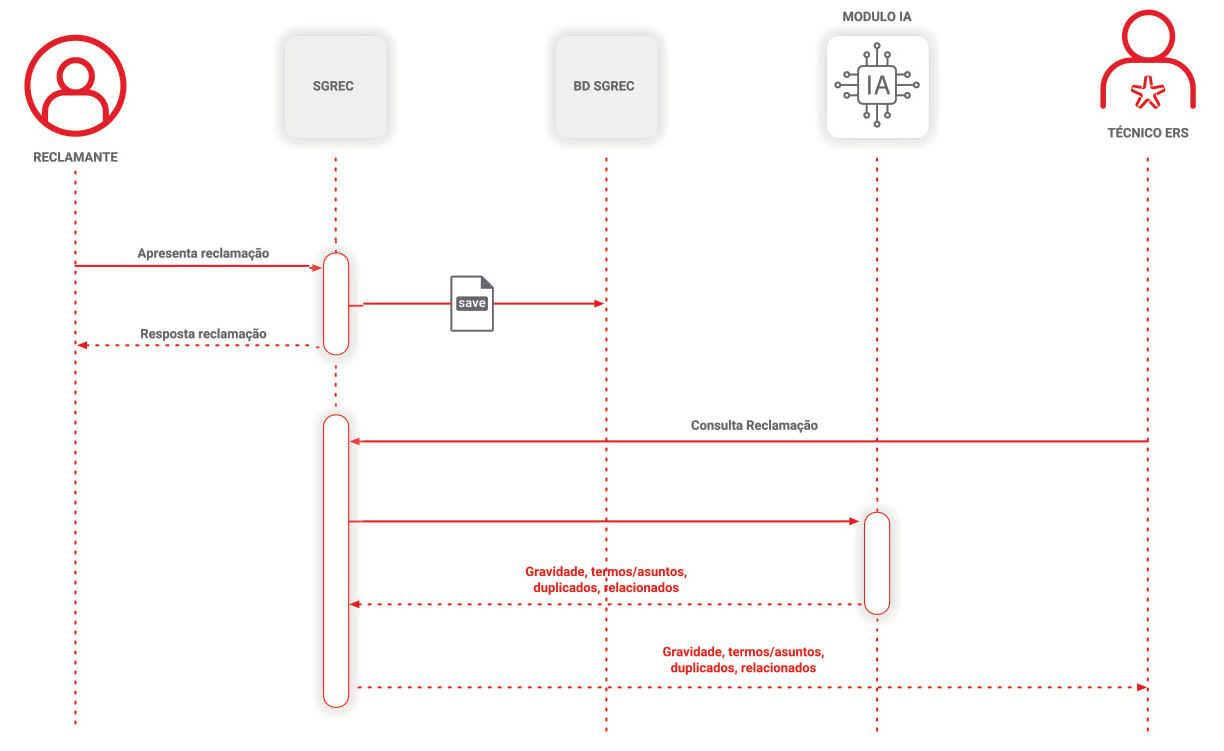
Figura 1 - Fluxo de informação e bases de dados da ERS utilizadas no tratamento de reclamações
Legenda:
SGREC – Sistema de gestão de reclamações da ERS
BD SGREC – Base de dados do SGREC
Classificação de reclamações por Temas e Assuntos
Na classificação de reclamações por temas/ assuntos identificaram-se os seguintes desafios:
⦁ Necessidade de combinar várias fontes de informação para identificar os temas/assuntos visados nos factos reclamados (exemplo, o conteúdo das reclamações, as sínteses da reclamação, as alegações do prestador remetidas à ERS, entre outros).
⦁ Problema relacionado com o facto de cada reclamação poder ser associada a mais do que um tema/ assunto
⦁ Existência de vários temas, sendo que cada tema pode contar um ou mais assuntos específicos
⦁ Impossibilidade de lidar com histórico de dados no caso de reclamações manuscritas
Nesta fase do projeto utilizaram-se classificadores binários, tais como Random Forest e Support Vector Machine (SVM), para a identificação de multilabeling e efetuou-se um pré-processamento dos dados com limpeza de texto.

Figura 2 – Exemplificação da deteção automática dos temas e assuntos
Os modelos de Inteligência Artificial pressupõem o retreino constante dos classificadores utilizados, para a garantia da aprendizagem automática.
Identificação de reclamações duplicadas e relacionadas entre si
A identificação de reclamações duplicadas ou relacionadas pressupõe a identificação e extração do processo REC[4]de determinadas variáveis que permitem a comparabilidade entre reclamações, tais como referências dos processos, dados do prestador, dados do utente, datas de ocorrência, entre outros.
Foi utilizada a abordagem de fuzzy matching tirando partido de diversos tipos de dados disponíveis.
Os resultados são apresentados de acordo com a percentagem de similaridade detetada entre múltiplos processos de reclamações, comparando as diversas variáveis disponíveis em cada caso.
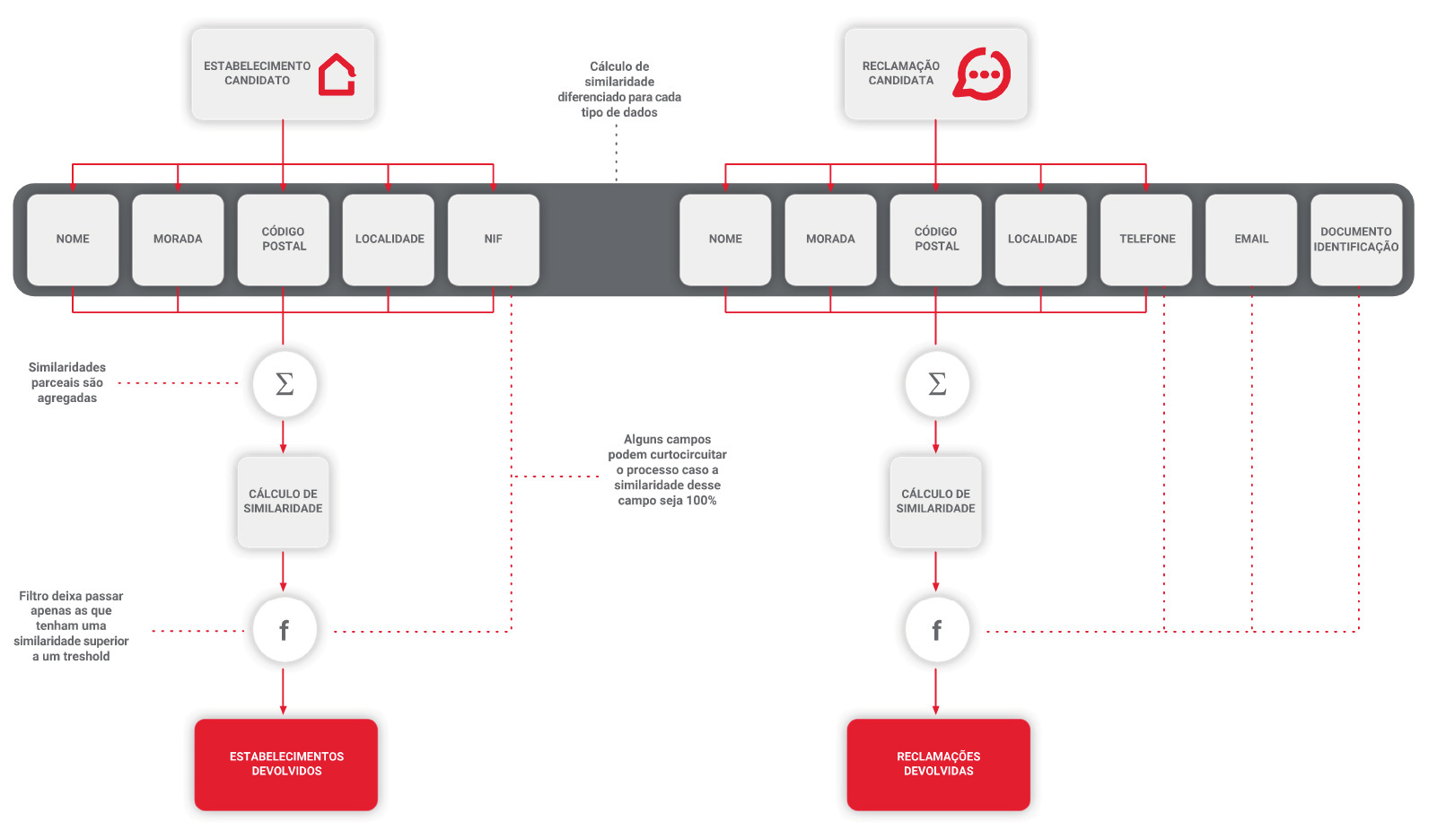
Figura 3 – Processo de identificação de reclamações duplicadas ou relacionadas entre si
[4] A informação avaliada no âmbito do processo REC é referente, não só aos factos reclamados, mas também às alegações/ resposta que o prestador envia ao utente e à ERS, por também esta ter informação essencial sobre a situação em análise.
Configuração de níveis de gravidade no módulo de Inteligência Artificial
Foi desenvolvida uma matriz de risco flexível com eixos configuráveis, que permite a seleção de múltiplas variáveis para classificar as reclamações em termos de gravidade dos factos reclamados.
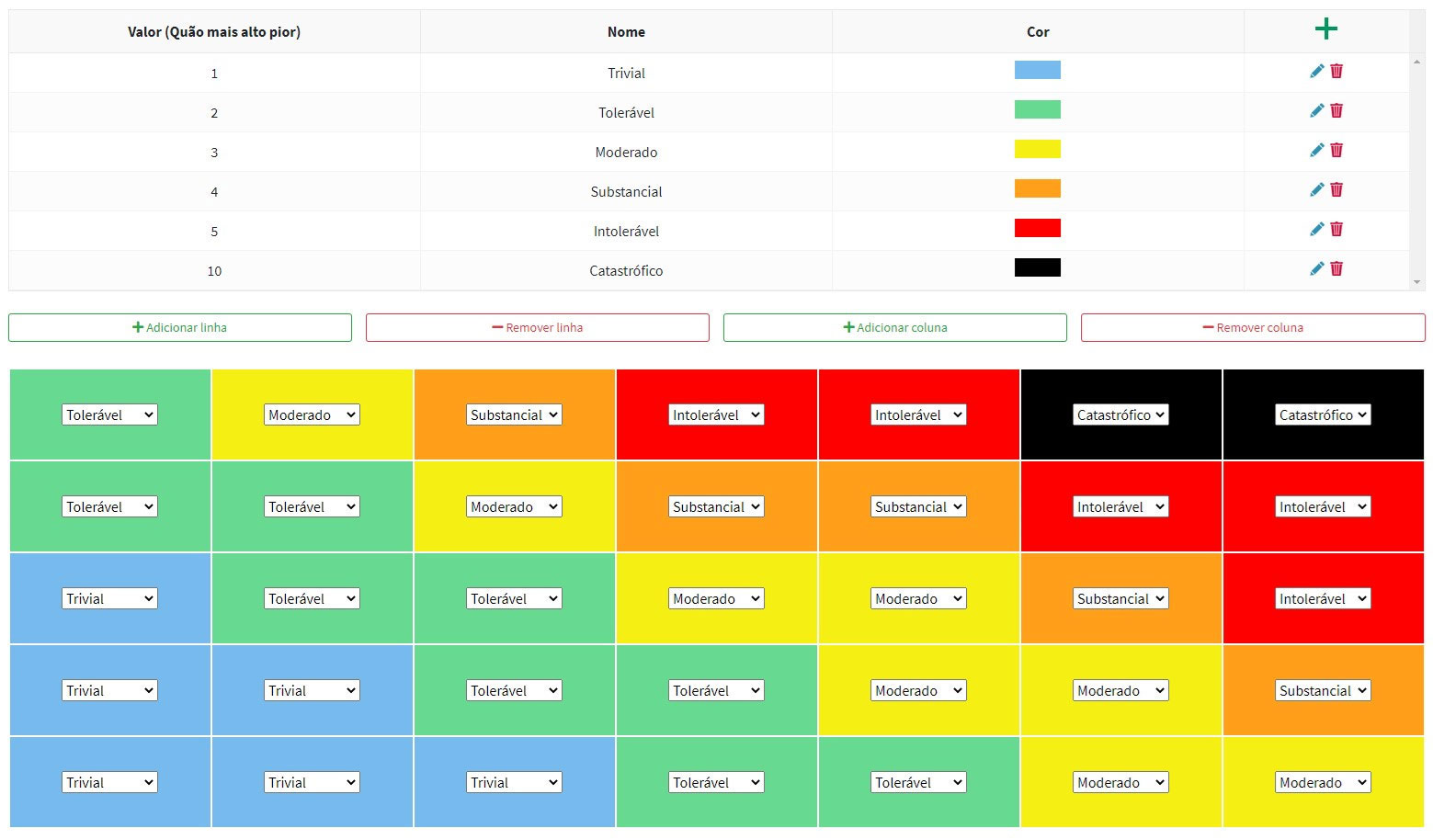
Figura 4 – Matriz de risco flexível para identificação do nível de gravidade de uma reclamação
A solução permite ainda configurar alarmística que poderá espoletar diferentes notificações à ERS.
Resultados
Os resultados obtidos com o fim da primeira fase permitiram avaliar positivamente a prova de conceito, avançando para a fase B com as atividades de implementação da solução em produção.
Os primeiros resultados conseguiram perspetivar uma melhoria da eficácia e ganhos de eficiência em processos internos da ERS, com os algoritmos de deteção de duplicados e relacionados, mas também com a classificação de gravidade que permite a priorização da atenção da ERS na monitorização, acompanhamento e tratamento das reclamações recebidas.
Detalhe Técnico
Numa primeira fase (fase A) foi realizada a análise de similaridades e de palavras-chave cujo resultado foi decisivo para o processo de deteção de duplicados e para a classificação de reclamações por tema.
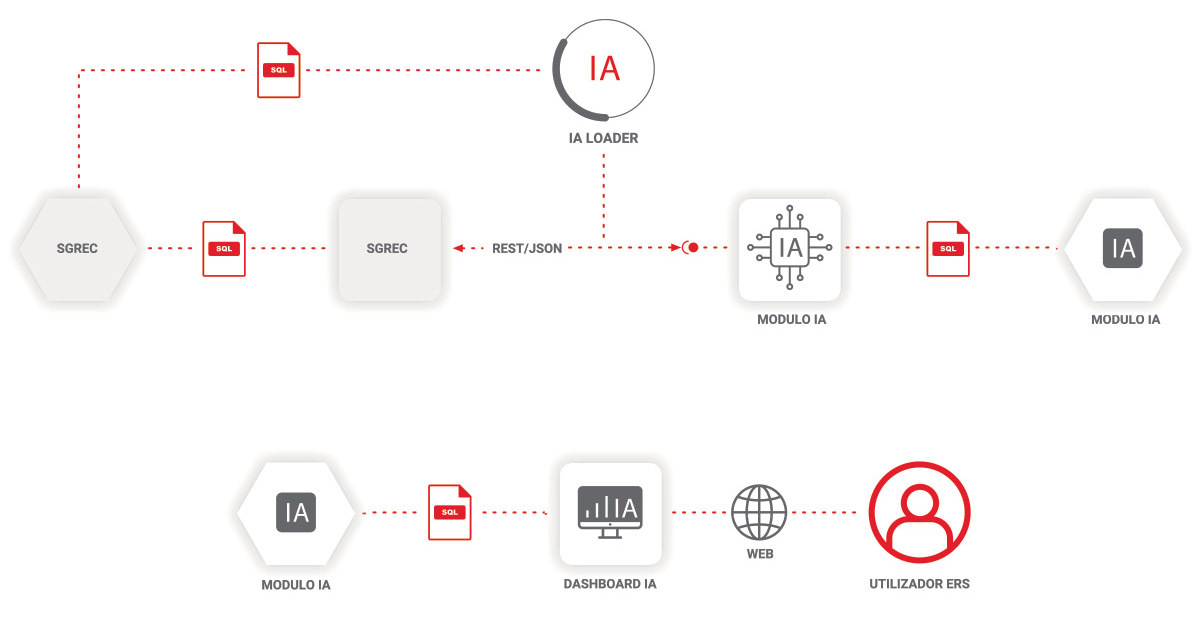
Legenda:
SGREC /SRER – Soluções existentes da ERS para gestão da informação dos prestadores, reclamações e atividade de licenciamento… (complementar).
IA Loader – Ferramenta para ingestão dos dados do SGREC/SRER para a base de dados do módulo de IA.
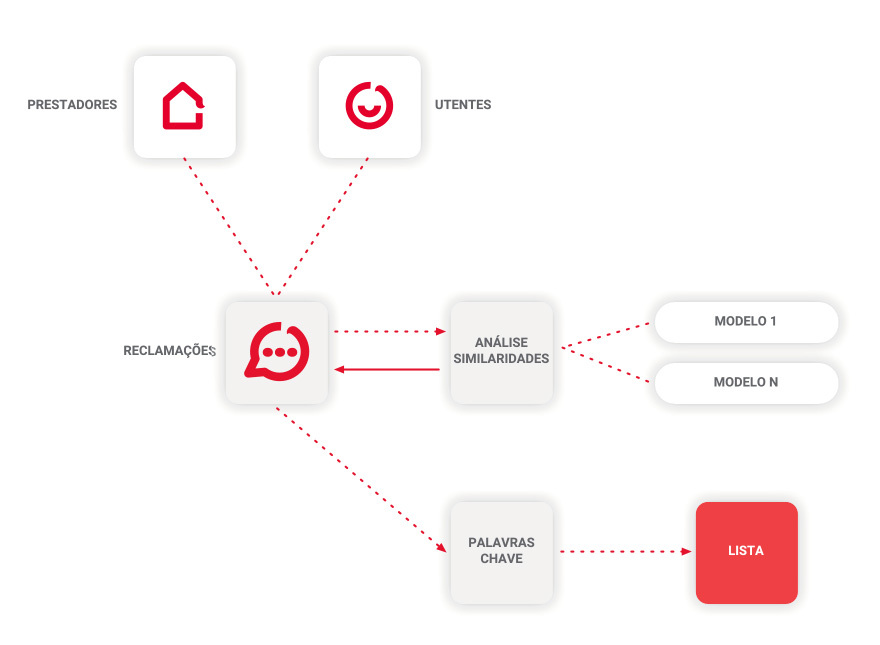
Nesta fase, o processo seguiu com a definição de um modelo para deteção de duplicados (estabelecimentos e reclamações) e um modelo para classificação de cada reclamação por temas, usando os modelos mais adequados definidos no processo anterior.
O processo de deteção de duplicados retorna para o utilizador informação sobre a probabilidade de uma determinada reclamação ser duplicada de outra ou outras reclamações, informando quais se for o caso.
Foram utilizadas as variáveis observadas na figura 1 e a distância de Levenshtein para determinar a similaridade.
Para a classificação por temas, foi utilizada uma amostra com 373977 elementos extraídos do processo REC[5], quando existiam, em formato digital. Foi utilizada a análise de frequência das palavras.
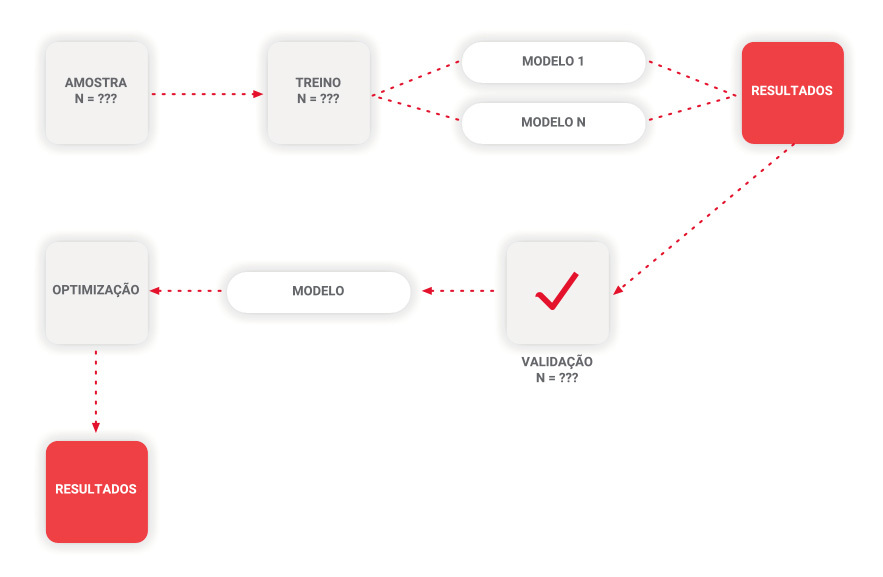
Para a classificação das reclamações quanto à prioridade (relacionado com o nível de risco), foi utilizada a aprendizagem computacional, tendo sido experimentados diversos modelos supervisionados. Foi utilizado um dataset com dimensão N que corresponde às reclamações entre o ano 2018 e o ano 2020. Os modelos mais promissores foram otimizados, primeiro através da análise e reformulação do dataset e, numa segunda fase, por ajuste dos hiperparâmetros do modelo.
A figura plasma o processo de treino, validação e otimização do modelo de classificação da reclamação.
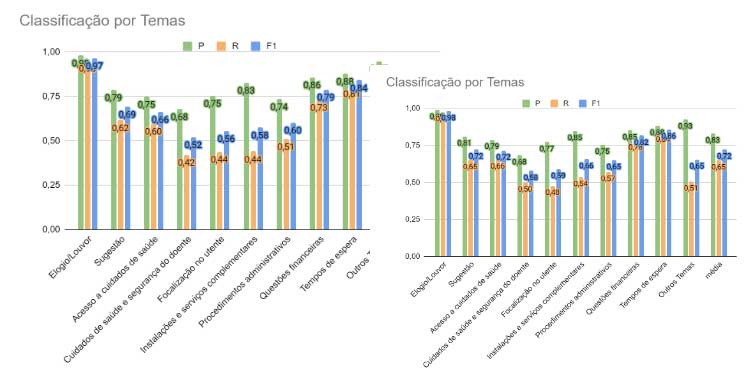
Figura 4. Processo de aprendizagem para a classificação de prioridade de uma reclamação
[5] A informação avaliada no âmbito do processo REC é referente, não só aos factos reclamados, mas também às alegações/ resposta que o prestador envia ao utente e à ERS, por também esta ter informação essencial sobre a situação em análise.
A criação de uma matriz de risco para os prestadores foi uma atividade fundamental para auxiliar na classificação da reclamação (em três níveis de importância). O processo para a construção da matriz de risco está representado na figura abaixo.
Processo de construção do modelo de classificação de risco
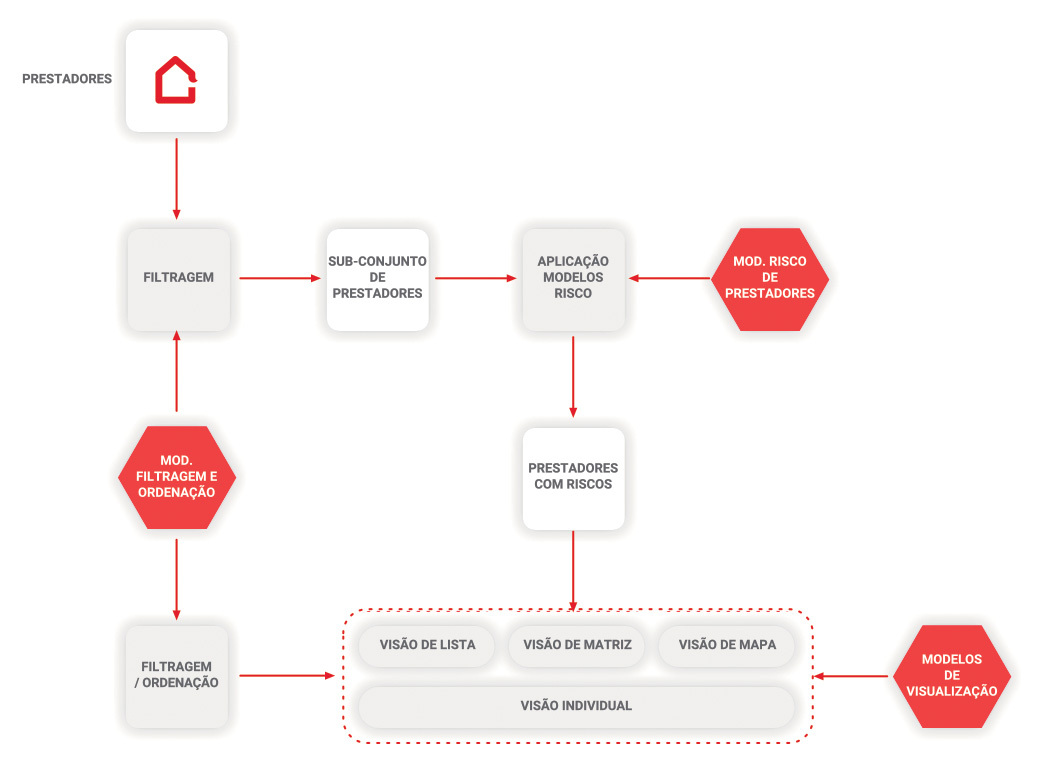
A matriz de risco é dinâmica, permitindo a parametrização de algumas variáveis de acordo com a perceção do utilizador.
A rápida perceção dos dados exige a criação de mapas de análise intuitivos e dinâmicos para cada um dos elementos em análise. As figuras 4 a 9 mostram alguns mapas propostos.
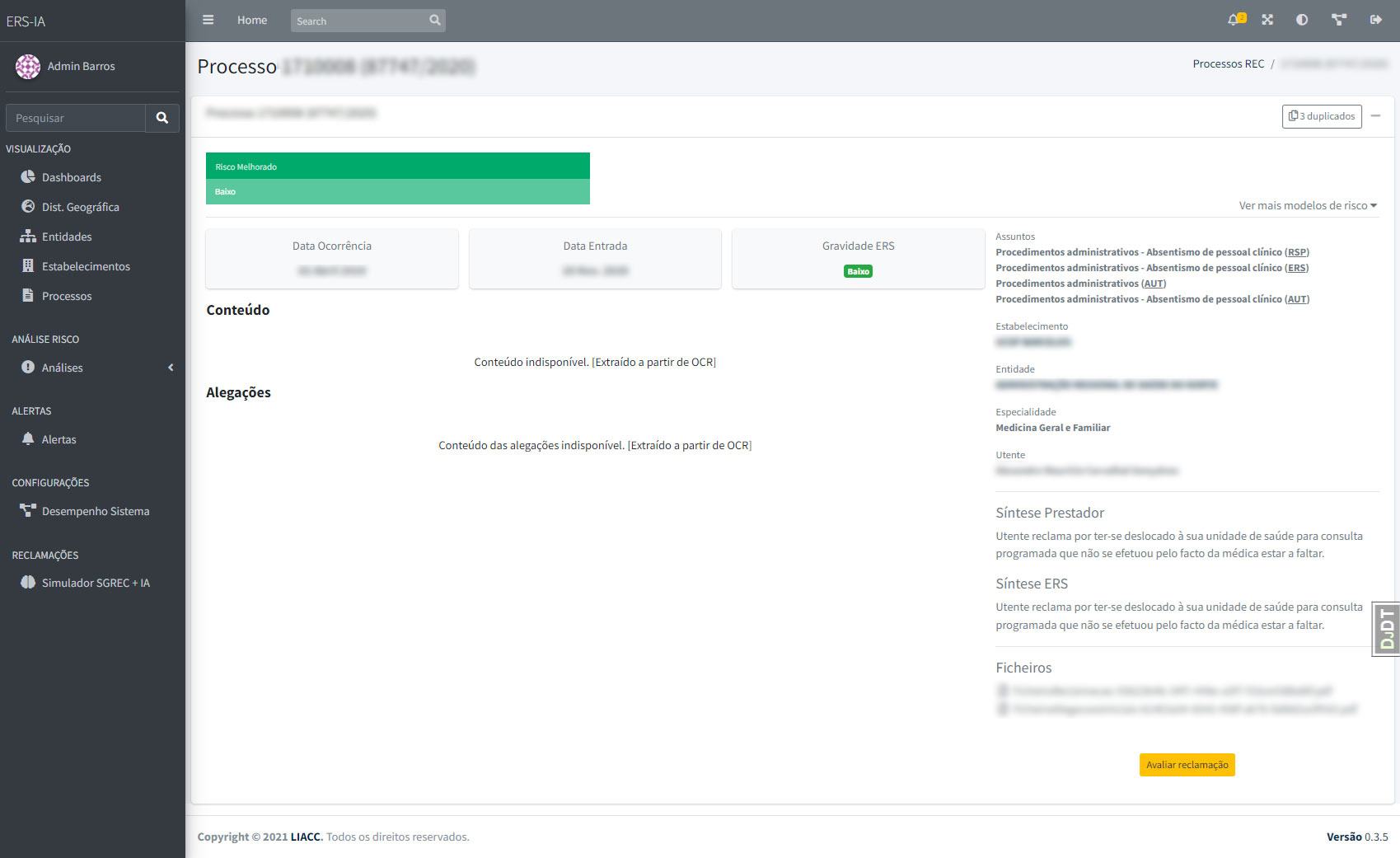
Figura 4. Processo REC
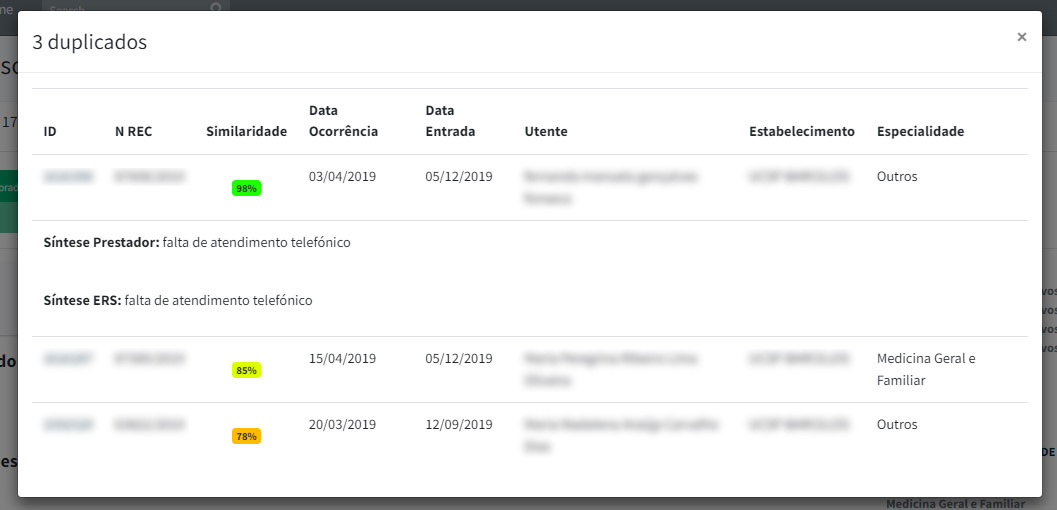
Figura 5. Análise de similaridades
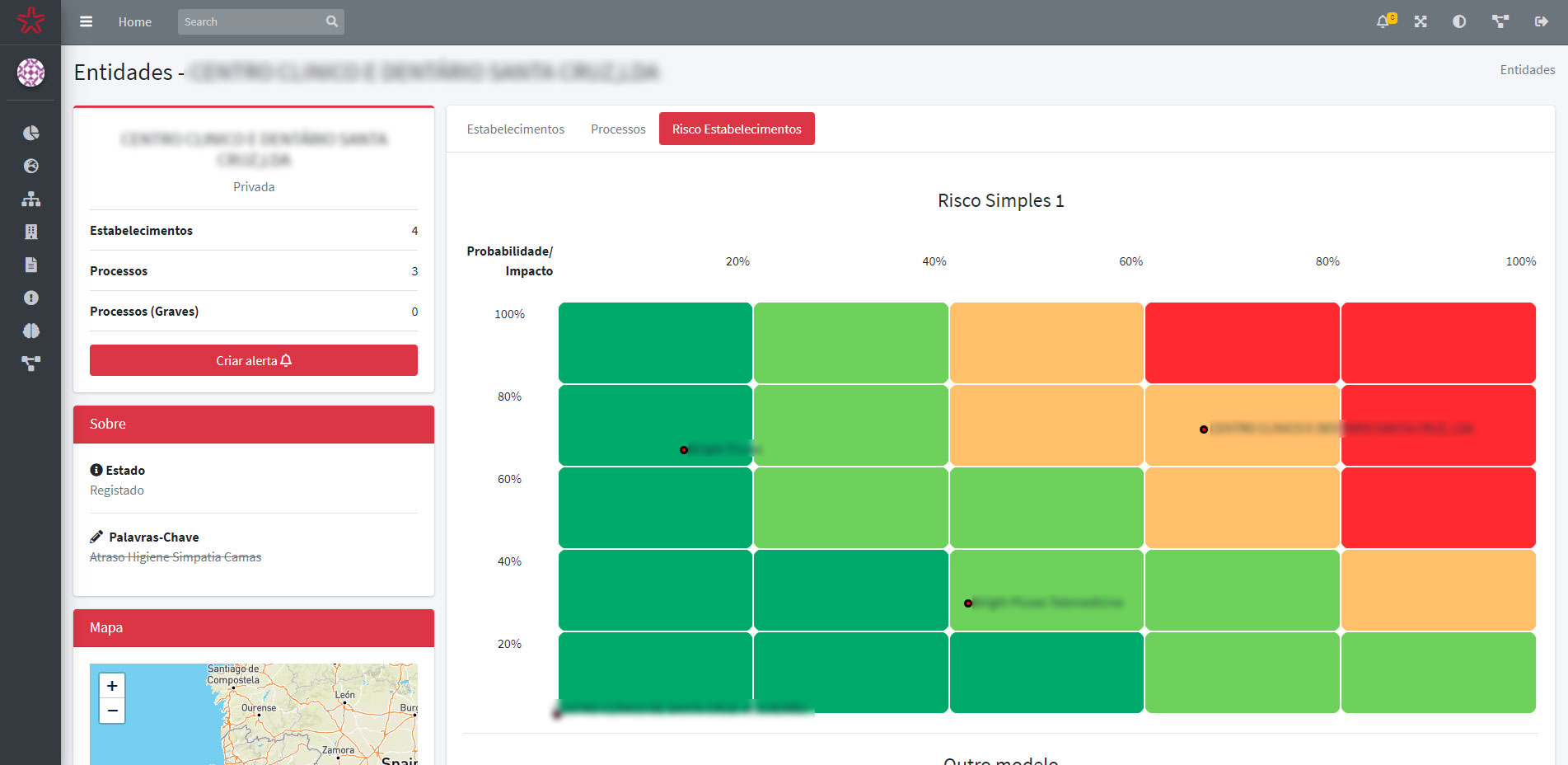
Figura 6. Dashboard da matriz de risco (visão 1)
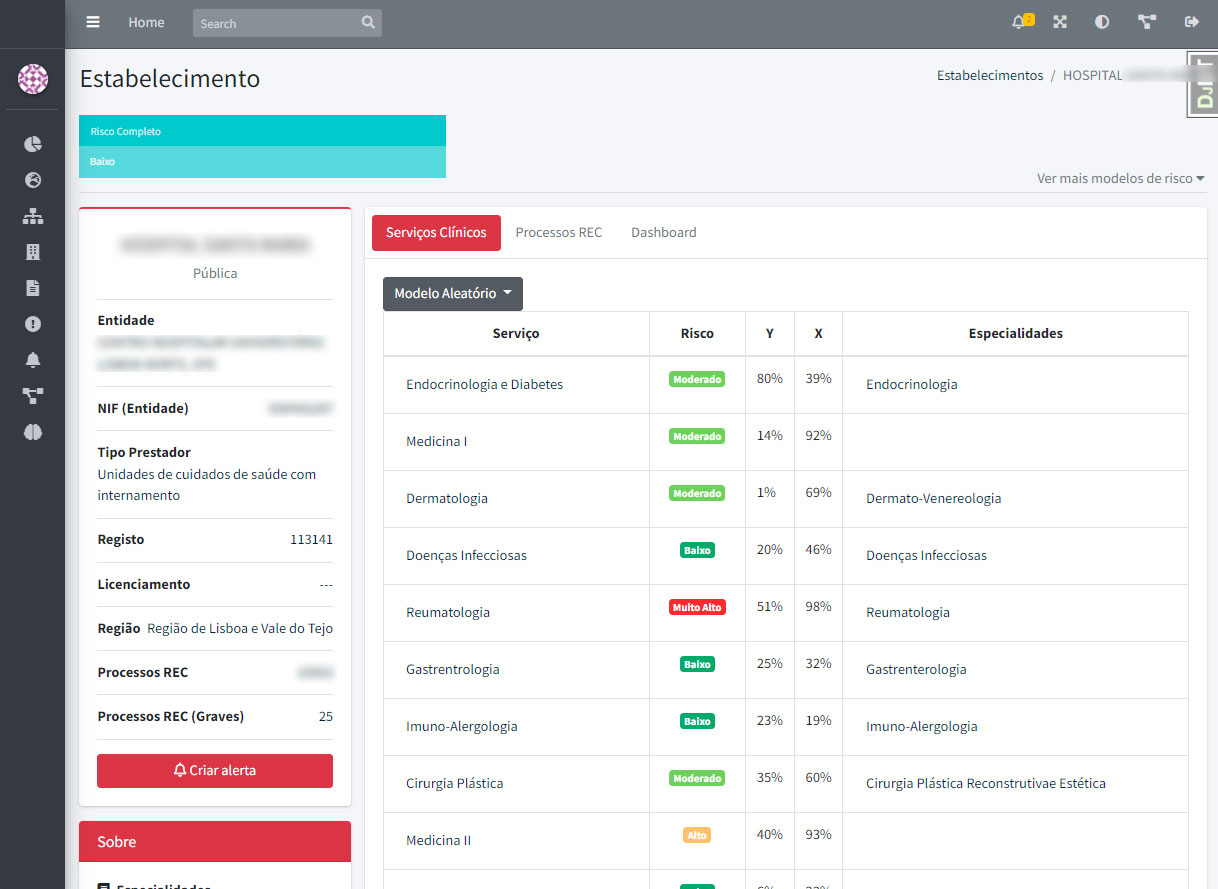
Figura 7. Dashboard da matriz de risco (visão 2)
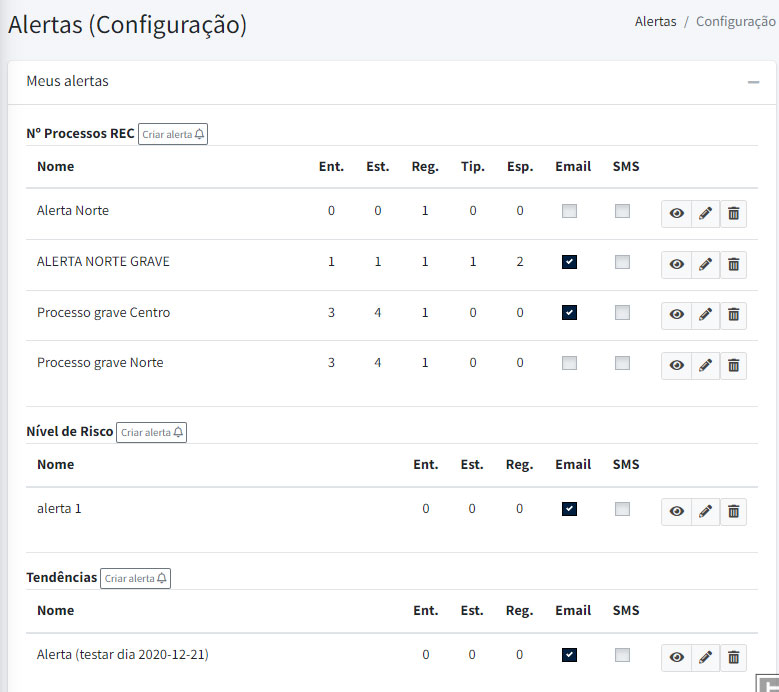
Figura 8. Alarmística
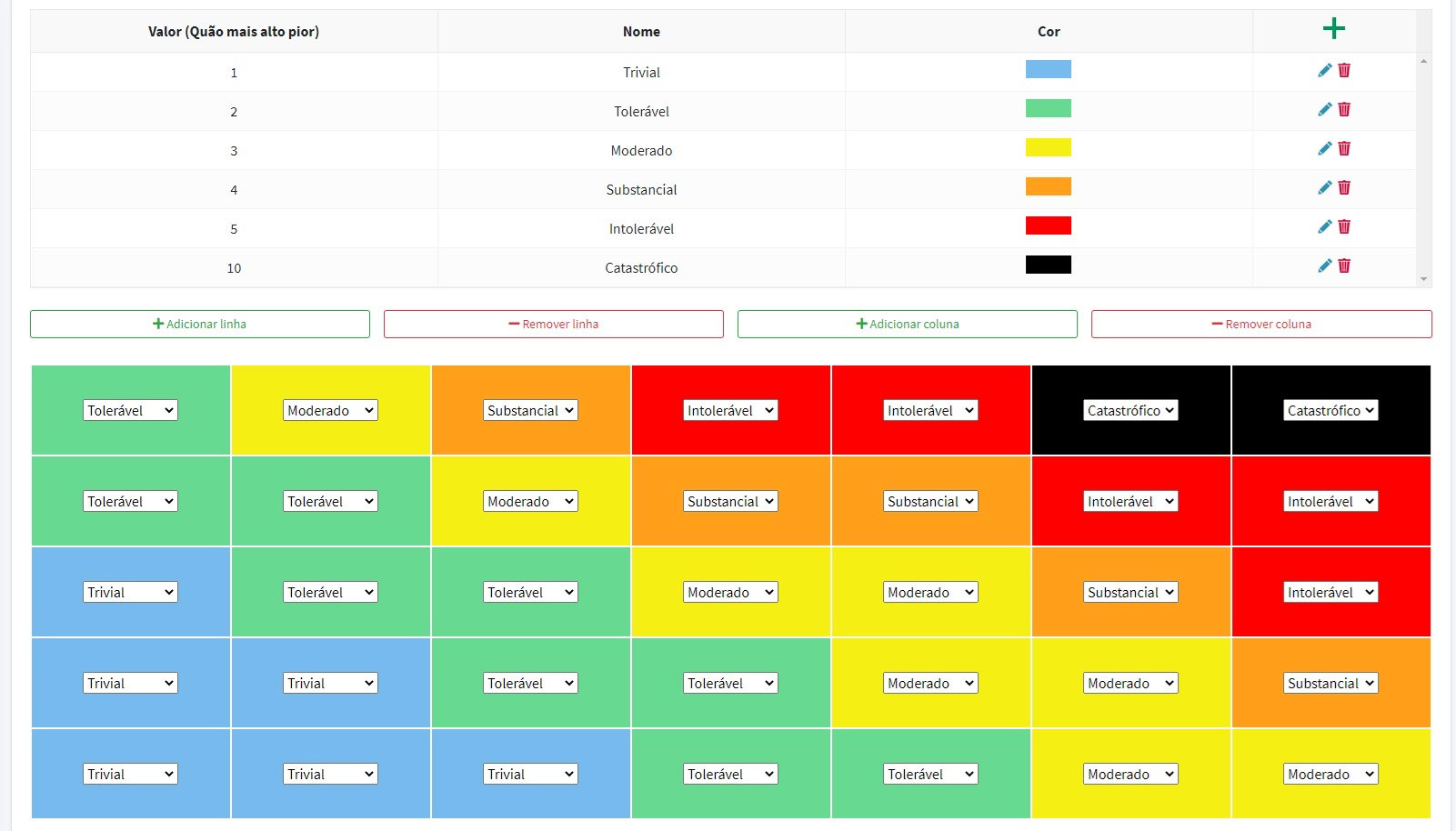
Figura 9 Matriz de risco
NOTÍCIAS E EVENTOS DO PROJETO
Participação da ERS nas Cybertalks do ISCTE de Sintra
Uma equipa da ERS participou nas Cybertalks do ISCTE de Sintra com a apresentação “A inteligência artificial na apreciação de reclamações pela ERS”, que contou com a participação ativa dos alunos da Licenciatura em Inteligência Artificial.
Saber MaisComportamento preditivo na saúde – a inteligência artificial na a...
Comportamento preditivo na saúde – a inteligência artificial na apreciação de reclamações pela ERS
Saber MaisSessão de apresentação - A inteligência artificial na apreciação ...
A ERS organizará uma sessão de apresentação, com o tema “A inteligência artificial na apreciação de reclamações pela ERS”.
Saber MaisSeminário Interno
A ERS organizou uma sessão de apresentação, com o tema “Projeto SAMA IA: A inteligência artificial na apreciação de reclamações pela ERS”, dirigida aos trabalhadores da ERS.
Saber Mais
![]()

309 309 309
(Chamada para rede fixa nacional)
(9h - 17h30)
222 092 350


Rua S. João de Brito, 621 L32
4100-455 Porto


